
One of my earliest “well that’s pretty cool” moments with LLMs was in October of last year. I was trying to find a particular panel of an excellent webcomic, Pictures for Sad Children, but the author had taken the entire series down in 2014.
Luckily, someone had uploaded an image dump of every page to imgur. Unluckily, it was 378 images long, and I can’t ⌘F on images. And even if I could, there was another issue: the list scroller on imgur uses virtualization to prevent having to load a presumably unbounded number of DOM elements, so only around 7 images were ever in the DOM at a time. Hm.
I could manually scroll through and re-read the whole series (which would be time well spent), but I was after the instant gratification to which modern living has me so accustomed.
#The Solution
Inspired by Simon Willison’s video scraping post, I wondered if I could take advantage of Google Gemini’s ability to process video to solve the problem of turning my unstructured image sequence into something structured and searchable.
I asked Claude to whip up a Puppeteer script1 to scroll through the page at a healthy clip and save a screen recording. (The recording was exactly one minute long—not bad for reading a seven-year-long anthology.) I also had it output a list of the image URLs it loaded and the timestamps of when it loaded them.
I fed the screen recording into AI Studio and asked it to:
In the latest provided video, find the timestamps at which the text “are you seeing anything that is strange” appear on screen. Return the timestamps in milliseconds as a JS array.
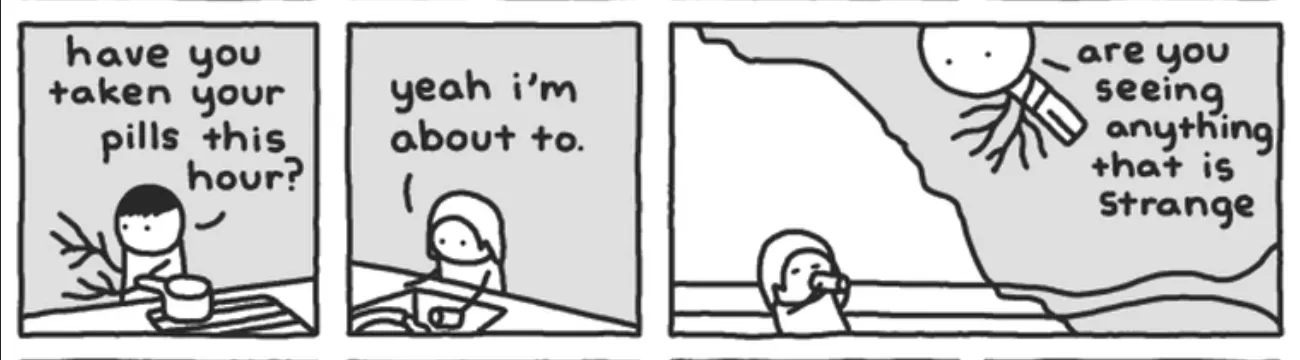
And it worked! I got one timestamp back, loaded up the image URLs from around that timestamp, and I had found the needle in the haystack and satisfied my nostalgic itch. Plus it felt extremely sci-fi to watch the page whiz by and have the computer process it.
I’d say the ability to create structured, operable data from unstructured content is definitely one of my favorite LLM superpowers.